
Sieci konwolucyjne 4: data augmentation
W poprzednich trzech częściach tutoriala w szczegółach poznaliśmy sieci konwolucyjne. Przyjrzeliśmy się operacji konwolucji, architekturze sieci konwolucyjnych oraz problemowi overfittingu. W klasyfikacji zbioru CIFAR-10 osiągnęliśmy wynik 81% na zbiorze testowym. Aby pójść dalej, musielibyśmy zmienić architekturę naszej sieci, poeksperymentować z hiperparametrami lub uzyskać więcej danych. Dwa pierwsze rozwiązania zostawiam dla was, 😉 a sam będę chciał w tej części tutoriala przedstawić sieci więcej danych. Skorzystam przy tym z tzw. data augmentation, czyli sztucznego wygenerowania dużej ilości nowych danych.
W czwartej części tutoriala dowiesz się między innymi:
- Czym jest data augmentation?
- Jak skorzystać z generatora danych z biblioteki Keras?
- Jak sztucznie wygenerować nowe dane dla zbioru CIFAR-10?
- Jak poradzi sobie nasz model na zbiorze sztucznie wygenerowanych danych?
Czym jest data augmentation?
Jak już wspominałem w poprzedniej części tutoriala, jeżeli mamy do czynienia z zamkniętym zbiorem danych, czyli takim, którego nie można w istotny sposób powiększyć lub jego powiększenie jest bardzo kosztowne, możemy sięgnąć po mechanizm tzw. data augmentation. Jest to szczególnie wartościowa technika w przypadku analizy obrazów. Dlaczego? Dlatego, że obrazy są podatne na drobne modyfikacje, które dla algorytmu będą nową daną, choć dla ludzkiego oka będą nadal w zasadzie tym samym. Co więcej, takie „drobne modyfikacje” występują w świecie rzeczywistym. Stojąc naprzeciwko samochodu, możemy patrzeć na niego centralnie lub lekko z boku. Będzie to nadal ten sam pojazd i na pewno będzie to dla naszego mózgu samochód. Dla algorytmu spojrzenie na obiekt z innej perspektywy jest cenną informacją pozwalającą lepiej generalizować proces uczenia.
Co w zasadzie możemy zrobić z obrazkiem, który chcemy sztucznie przetworzyć? Teoretycznie mamy nieskończenie wiele rozwiązań: możemy obrazek lekko obrócić, w dowolnym kierunku, o dowolny kąt. Przesunąć w lewo, w prawo, w górę i dół. Zmienić jego kolory lub dokonać innych mniej lub bardziej subtelnych zmian, które dadzą modelowi tony nowych danych. W praktyce zbiór kilkudziesięciu tysięcy obrazków może się stać zbiorem z milionami elementów. Jest to pole, na którym możliwości są naprawdę duże. Jako ciekawostka: technologie związane z autonomicznymi pojazdami są trenowane również na zbiorach danych sztucznie generowanych, np. z wykorzystaniem środowisk realistycznych gier, takich jak GTA.
Generowanie danych z biblioteką Keras
Biblioteka Keras oferuje zestaw pomocnych narzędzi do generowania danych. Spróbujmy przetworzyć generatorem widziany już uprzednio obrazek budynku na Krecie. W pierwszej kolejności dokonujemy niezbędnych importów i definiujemy funkcję, która załaduje obraz z pliku i skonwertuje go do tablicy numpy:
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
%matplotlib inline
def convert_image(file):
return np.array(Image.open(file))
Ładujemy obrazek, który można pobrać sobie tutaj, wyświetlamy kształt tablicy numpy oraz sam obrazek:
image = convert_image(r'<<wpis_ścieżkę_do_pliku_na_dysku>>\house-small.jpg')
image.shape
>>> (302, 403, 3)
plt.imshow(image)

Do generowania danych będziemy używali metody flow(x,y) z klasy ImageDataGenerator. Abyśmy byli w stanie użyć jej poprawnie, musimy oczywiście zaimportować klasę, ale także przystosować odpowiednio dane. Metoda oczekuje tensora x, w którym pierwszą pozycją będzie indeks. W naszym przypadku będzie tylko jeden element, ale metoda i tak wymaga indeksu. Dana wejściowa y to labelki, które nie są nam potrzebne dla tego prostego eksperymentu, niemniej musimy je dostarczyć. Stąd:
from tensorflow.keras.preprocessing.image import ImageDataGenerator
x = np.expand_dims(image, 0)
x.shape
>>> (1, 302, 403, 3)
y = np.asarray(['jakakolwiek-labelka'])
Następnie tworzymy obiekt generatora, przekazując odpowiednie parametry. W specyfikacji dostępnych jest ich naprawdę sporo, poniżej zaprezentowałem kilka przykładowych:
datagen = ImageDataGenerator(
width_shift_range=0.2, # przesunięcie wzdłuż osi x
height_shift_range=0.2, # przesunięcie wzdłuż osi y
rotation_range=20, # rotacja
horizontal_flip=True, # odwrócenie poziome
vertical_flip = True, # odwrócenie pionowe
rescale=1./255, # parametr niezbędny, aby dobrze zwizualizować dane
shear_range=0.25, # przycinanie obrazu
zoom_range=0.25, # zoom
)
Pozostaje teraz wywołać metodę flow(x, y), przekazując do niej przygotowane dane i odbierając oraz wyświetlając wygenerowane obrazy.
figure = plt.figure()
i = 0
for x_batch, y_batch in datagen.flow(x, y):
a = figure.add_subplot(5, 5, i + 1)
plt.imshow(np.squeeze(x_batch))
a.axis('off')
if i == 24: break
i += 1
figure.set_size_inches(np.array(figure.get_size_inches()) * 3)
plt.show()
Wynik? Dosłownie i w przenośni nieco postawiony na głowie 😉 i trochę „przerysowany”, bo niektóre parametry mają ustawione duże wartości, ale dobrze oddaje możliwości generatora. Możecie sami poeksperymentować z ustawieniami.

Data augmentation na zbiorze CIFAR-10
Uzbrojeni w generator, możemy jeszcze raz podejść do klasyfikacji zbioru CIFAR-10. Większość kodu była już omawiana w poprzednich częściach tutoriala, więc podam ją tu tylko dla zapewnienia spójności i jasności. Na wstępie wykonujemy niezbędne importy, załadowanie zbioru oraz budujemy model:
import numpy as np
%tensorflow_version 2.x
import tensorflow
import matplotlib.pyplot as plt
%matplotlib inline
from tensorflow import kerasprint(tensorflow.__version__)print(keras.__version__)>>> 1.15.0>>> 2.2.4-tffrom tensorflow.keras.datasets import cifar10(x_train,y_train), (x_test,y_test) = cifar10.load_data()from tensorflow.keras.models import Sequentialfrom tensorflow.keras.optimizers import RMSpropfrom tensorflow.keras.layers import Convolution2D, MaxPool2D, Flatten, Dense, Dropout, BatchNormalizationfrom tensorflow.keras import regularizersfrom tensorflow.keras.utils import to_categoricalmodel = Sequential([ Convolution2D(filters=128, kernel_size=(5,5), input_shape=(32,32,3), activation='relu', padding='same'), BatchNormalization(), Convolution2D(filters=128, kernel_size=(5,5), activation='relu', padding='same'), BatchNormalization(), MaxPool2D((2,2)), Convolution2D(filters=64, kernel_size=(5,5), activation='relu', padding='same'), BatchNormalization(), Convolution2D(filters=64, kernel_size=(5,5), activation='relu', padding='same'), BatchNormalization(), MaxPool2D((2,2)), Convolution2D(filters=32, kernel_size=(5,5), activation='relu', padding='same'), BatchNormalization(), Convolution2D(filters=32, kernel_size=(5,5), activation='relu', padding='same'), BatchNormalization(), MaxPool2D((2,2)), Convolution2D(filters=16, kernel_size=(3,3), activation='relu', padding='same'), BatchNormalization(), Convolution2D(filters=16, kernel_size=(3,3), activation='relu', padding='same'), BatchNormalization(), Flatten(), Dense(units=32, activation="relu"), Dropout(0.15), Dense(units=16, activation="relu"), Dropout(0.05), Dense(units=10, activation="softmax")])optim = RMSprop(lr=0.001)model.compile(optimizer=optim, loss='categorical_crossentropy', metrics=['accuracy'])Po przygotowaniu i pomyślnym skompilowaniu modelu definiujemy generator. Zakładamy, że dane będą rotowane o 10 stopni, dopuszczamy odwrócenie poziome, ale już nie pionowe, aby nie „stawiać rzeczy na głowie”. Generator będzie też przesuwał obrazki w pionie i poziomie o 10%. Dopuszczalny jest też niewielki zoom i shear. Pamiętajmy, że obrazki są niewielkie i mocniejsze modyfikacje mogą sprawić, że obraz będzie trudny do rozpoznania nawet dla człowieka:
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator( rotation_range=10, horizontal_flip=True, vertical_flip = False, width_shift_range=0.1, height_shift_range=0.1, rescale = 1. / 255, shear_range=0.05, zoom_range=0.05,)Potrzebujemy również one-hot encodingu dla labelek zbiorów uczących i testowych. Ustalamy wielkość batcha i generator w zasadzie gotowy:
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
batch_size = 64
train_generator = datagen.flow(x_train, y_train, batch_size=batch_size)
Powyższy generator będzie źródłem danych dla procesu uczenia. Co jednak ze zbiorem walidacyjnym, który umożliwi nam śledzenie postępów? Otóż musimy zdefiniować odrębny generator, który jednak nie będzie w żaden sposób modyfikował źródłowych obrazków:
datagen_valid = ImageDataGenerator(
rescale = 1. / 255,
)
x_valid = x_train[:100*batch_size]
y_valid = y_train[:100*batch_size]
x_valid.shape[0]
>>>6400
valid_steps = x_valid.shape[0] // batch_size
validation_generator = datagen_valid.flow(x_valid, y_valid, batch_size=batch_size)
Jak widać powyżej, zbiór, którego proces uczenia będzie używał do walidacji, będzie miał wielkość 100 paczek danych. Na podstawie wielkości tego zbioru i wielkości paczki wyliczamy również ilość kroków walidacji – dane te będą potrzebne do wywołania funkcji uczenia.
history = model.fit_generator(
train_generator,
steps_per_epoch=len(x_train) // batch_size,
epochs=120,
validation_data=validation_generator,
validation_freq=1,
validation_steps=valid_steps,
verbose=2
)
Zwróćcie uwagę, że nie używamy metody fit(), jak to miało miejsce uprzednio, lecz metody fit_generator(), która przyjmuje na wejściu generator z danymi uczącymi oraz (opcjonalnie) generator danych walidacyjnych. Mając tak dużo danych, będziemy uczyli 120 zamiast 80 epok, licząc na to, że unikniemy overfittingu.
>>> Epoch 1/120
>>> Epoch 1/120
>>> 781/781 - 49s - loss: 1.8050 - acc: 0.3331 - val_loss: 1.5368 - val_acc: 0.4581
>>> Epoch 2/120
>>> Epoch 1/120
>>> 781/781 - 41s - loss: 1.3230 - acc: 0.5249 - val_loss: 1.1828 - val_acc: 0.5916
>>> Epoch 3/120
(...)
>>> 781/781 - 39s - loss: 0.1679 - acc: 0.9473 - val_loss: 0.1484 - val_acc: 0.9463
>>> Epoch 119/120
>>> Epoch 1/120
>>> 781/781 - 38s - loss: 0.1708 - acc: 0.9466 - val_loss: 0.1538 - val_acc: 0.9538
>>> Epoch 120/120
>>> Epoch 1/120
>>> 781/781 - 39s - loss: 0.1681 - acc: 0.9486 - val_loss: 0.1379 - val_acc: 0.9534
W procesie uczenia otrzymaliśmy accuracy na poziomie 95% i to dla obu zbiorów. Widać to zresztą również na poniższym wykresie:
print(history.history.keys())
>>> dict_keys(['loss', 'acc', 'val_loss', 'val_acc'])
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Valid'], loc='upper left')
plt.show()
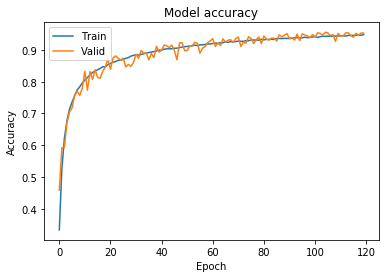
Ze względu na brak overfittingu i widoczny gołym okiem progres parametrów uczenia do samego końca, być może moglibyśmy pokusić się o dalsze zwiększenie ilości epok.
Sprawdźmy jak wyuczony model poradzi sobie na danych testowych, których jeszcze nie widział.
x_final_test = x_test / 255.0
eval = model.evaluate(x_final_test, y_test)
>>> 10000/10000 [==============================] - 3s 314us/sample - loss: 0.5128 - acc: 0.8687
A zatem osiągnęliśmy accuracy na poziomie 87%, o 6% więcej niż w wersji modelu bez generowania danych.
Najważniejsze jednak, że model wykazuje ochotę do dalszego uczenia, bez szkody dla accuracy na zbiorze walidacyjnym i testowym.
To już ostatni post w tym tutorialu. Mam nadzieję, że udało mi się przybliżyć kilka ciekawych zagadnień związanych z sieciami konwolucyjnymi.
Masz pytanie? Zadaj je w komentarzu.
Spodobał ci się post i cały tutorial? Będzie mi miło, gdy go polecisz.
Do zobaczenia wkrótce, przy okazji omawiania innego ciekawego tematu!
Anonim
5 czerwca 2022at21:20Super materiał, przerobiłem cały, dziękuję, jestem na prawdę wdzięczny!
AI Geek Programmer
7 czerwca 2022at22:24Hej, fajnie, że materiał się przydał i spodobał – dzięki!
Anonim
1 października 2022at12:47Ciekawy materiał. Dzięki za wysiłek włożony w jego przygotowanie!
AI Geek Programmer
1 października 2022at22:50Dzięki za uznanie!